10. Управление кластерами услуги
10.1. Общие положения
Инсталляции приложений в рамках Datamart Platform Studio могут функционировать, как самостоятельные компоненты, так и в составе кластера. Если приложения собраны в кластер, то Программа позволяет выполнять задачи по всем инсталляциям (на уровне кластера). Для инсталляций, собранных в кластер, Datamart Platform Studio обеспечивает пакетную установку, удаление, переустановку и другие дополнительные операции. Все эти задачи будут выполняться автоматически для каждой инсталляции входящей в кластер.
Сборка инсталляций приложений в единый кластер допускается только для приложения одной и той же версии и одного бандла. Приложение одной версии, но находящиеся в разных бандлах не допускается собирать в кластер в рамках Datamart Platform Studio. Это ограничение контролируется в момент добавления инсталляции приложения в кластер.
Все инсталляции в кластере должны должны быть установлены на сервера в одной сети. Если требуется использовать сервера из разных сетей, то требуется обеспечить видимость серверов друг для друга по hostname и ip-адресам для корректного взаимодействия инсталляций в рамках одного кластера.
Примечание
В списке инсталляций Услуги для любых инсталляций, собранных в кластер, все действия должны выполняться из раздела меню управления Кластер. Данные действия будут применены не только к текущей инсталляции, но ко всему кластеру в целом.
Если требуется произвести действие для отдельной инсталляции в кластере, Datamart Platform Studio выведет пользователю предупреждение «Точно ли вы хотите выполнить действие для одной инсталляции кластера?», т.к. некоторые действия могут нарушить целостность кластера.
10.2. Добавление кластеров приложений
10.2.1. Добавление кластера
Для того, чтобы добавить кластер приложений в услугу нужно последовательно совершить следующие действия:
Добавить в Услугу инсталляцию приложения, на базе которого планируется создать кластер. Инсталляция должна иметь статус
Новая, т.е. добавлена, но физически не установлена на сервер. Установка будет производиться позднее для всех инсталляций кластера целиком.
Примечание
Можно добавить сразу несколько инсталляций приложения для кластера на разные сервера в ДЦ услуги.
Добавление приложений в услугу подробно описано в разделе Раздел 9 Управление инсталляциями приложений в услуге.
Зарегистрировать кластер приложений для соответствующего приложения
В программе Datamart Platform Studio кластер является логическим объектом, который необходимо предварительно зарегистрировать в услуге. Для этого перейдите в карточку услуги, выберите вкладку Кластеры и нажмите на кнопку Создать Кластер (см. Рисунок 10.2)
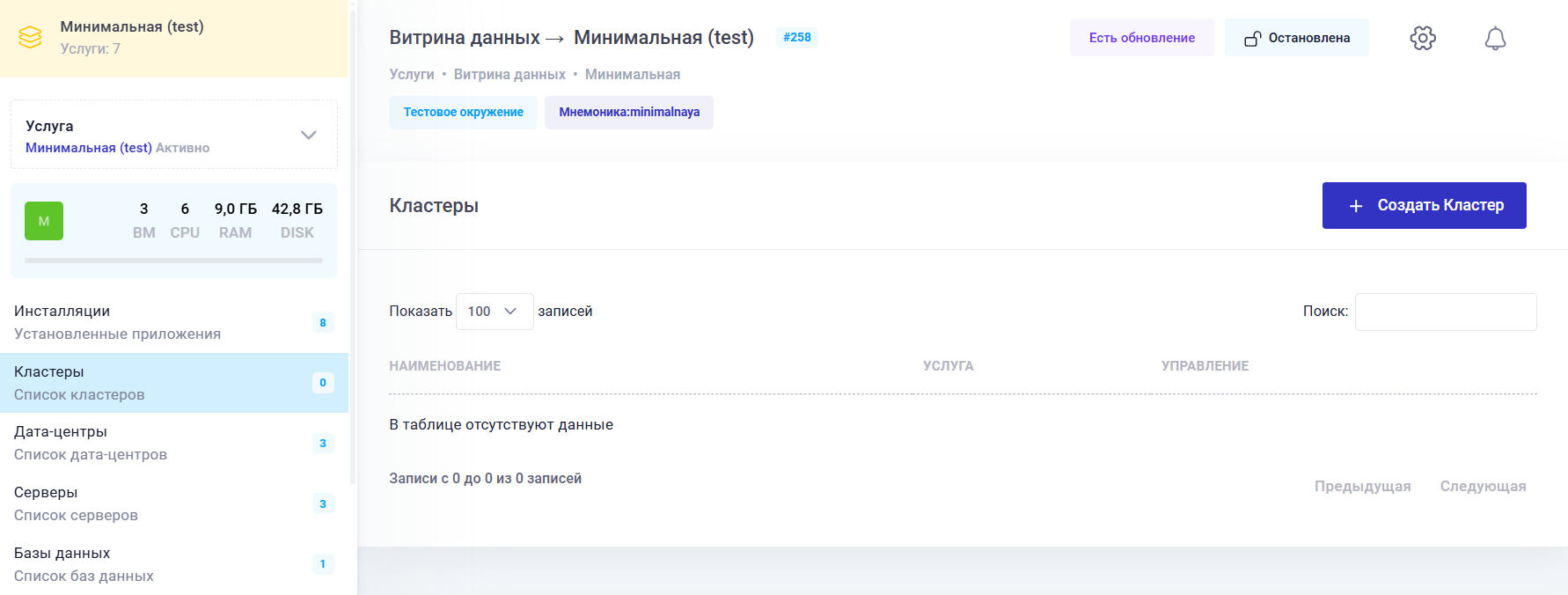
Рисунок 10.2 Создание кластера в Витрине.
После нажатия на данную кнопку введите наименование кластера и выберите, для какого приложения Услуги создается кластер.
Примечание
В списке приложений, для которых можно создать кластер будут доступны только те приложения, инсталляции которых уже добавлены в Услугу.
После создания кластера изменить приложение кластера невозможно. Если требуется поменять приложение кластера, то необходимо создать новый кластер, а старый удалить, предварительно удалив из него все инсталляции.
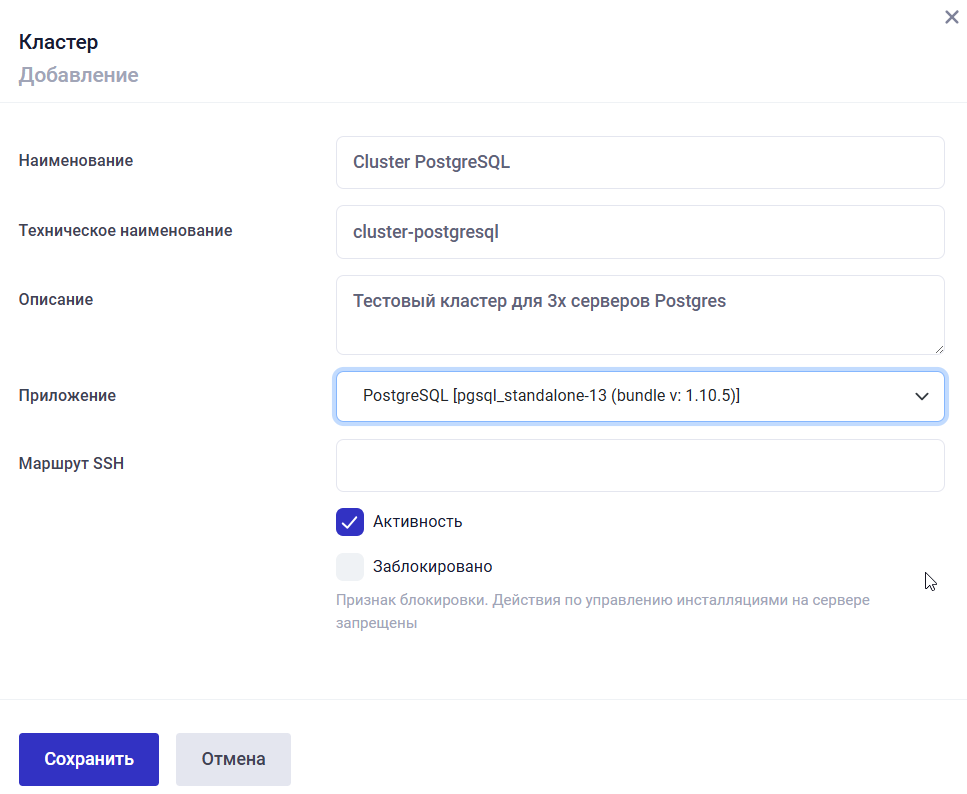
Рисунок 10.3 Карточка добавления кластера
После того, как создан логический объект Кластер для приложения, и перед запуском установки для кластера, в кластер можно добавить сколько угодно инсталляций приложения.
Если требуется добавить инсталляции в уже работающий кластер, см. Раздел 10.4.1 Добавление инсталляций в работающий кластер .
Добавить инсталляции приложений в кластер до необходимого количества.
Примечание
Количество инсталляций приложений в кластере определяется требованиями того или иного кластера. Например, для кластеров Zookeeper и Postgres DCS требуется обязательно установка нечётного числа инсталляций.
Запустить установку кластера
Для установки приложений кластера выберите действие «Установить» в меню управления кластером. В процессе установки кластера производится последовательная установка на серверы Услуги всех приложений кластера.
10.3. Создание универсального балансировщика для кластеров
При необходимости создания сервиса балансировщика для кластера или нескольких кластеров в рамках услуги, требуется установить отдельное приложение keepalived_haproxy из соответствующего бандла.
Для повышения надёжности, сервис балансировщика рекомендуется установить тоже, как отдельный кластер из двух инсталляций keepalived_haproxy.
Настройки конфигураций балансировки для каждого конкретного кластера поставляется в бандле соответствующего приложения для установки кластера в формате приложения с именем <имя_приложения>_haproxy
10.3.1. Список кластерных приложений, для которых предусмотрено использование универсального балансировщика
Список кластерных приложений, для которых предусмотрено использование универсального балансировщика:
Ядро Prostore;
СМЭВ QL;
СУБД Postgres;
СУБД Pangolin.
10.3.2. Список кластерных приложений, для которых не требуется использование балансировщика
Список кластерных приложений, для которых не требуется использование балансировщика:
Zookeeper;
Kafka;
Corax.
10.4. Ресайзинг кластеров приложений
10.4.1. Добавление инсталляций в работающий кластер
Если требуется добавить инсталляции в уже работающий кластер, то для этого нужно:
Добавить новую инсталляцию в кластер (со статусом
Новая);Из меню управления кластером повторно запустить команду
Установкадля кластера;
Консистентное добавление инсталляций в работающий кластер данным способом доступно для следующих типов приложений:
Zookeeper;
Kafka;
СУБД Postgres;
СУБД Pangolin;
СМЭВ QL;
Corax.
Примечание
При добавлении инсталляций приложений в кластер необходимо учитывать требование конкретного кластера к количеству инстансов.
10.4.2. Удаление инсталляций из работающего кластера
Если требуется удалить инсталляции из работающего кластера, то для этого нужно:
Запустить деинсталляцию для выбранной инсталляции или нескольких, если требуется удалить из кластера несколько инсталляций;
Из меню действий управления кластером запустить команду
Привязать (bind)
Консистентное удаление инсталляций из кластера данным способом доступно для следующих типов приложений:
Zookeeper;
Kafka;
СУБД Postgres;
СУБД Pangolin;
СМЭВ QL;
Corax.
Примечание
При удалении инсталляций приложений из кластера необходимо учитывать требование конкретного кластера к количеству инстансов.
10.5. Примеры настройки кластеров приложений
10.5.1. Особенности настройки кластера Zookeeper
При создании кластера Zookeeper необходимо учитывать, что в данном кластере требуется иметь строго нечётное количество инстансов (3, 5, 7 и т.д.).
Настройка кластера Zookeeper будет произведена плейбуками Datamart Platform Studio автоматически.
10.5.2. Особенности настройки кластера Kafka
При создании кластера Kafka необходимо учитывать, что в данном кластере рекомендуется иметь от 3-х инстансов и более. Минимальное количество = 2.
Настройка кластера Kafka будет произведена плейбуками Datamart Platform Studio автоматически.
10.5.3. Схема развертывания кластера Corax
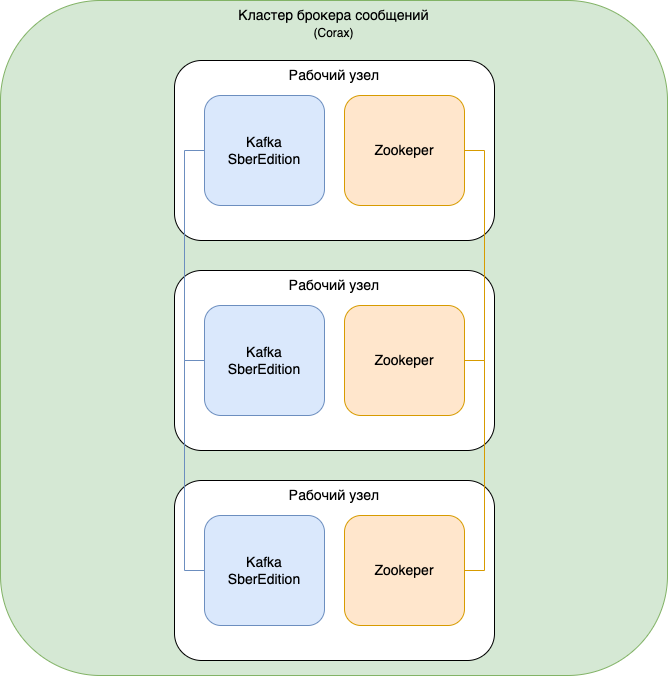
Рисунок 10.4 Схема развертывания кластера Corax для Витрин данных с показателем уровня доступности 99.5%
10.5.4. Установка и настройка кластеров Postgres и Pangolin
Примечание
В текущем разделе описывается установка кластера Postgres. Установка кластера Pangolin производится аналогичным образом.
Для установки кластера Postgres требуется производить установку приложения из кластерного бандла Postrgesql для витрины данных с haproxy.
Кластер Postgres (Pangolin) в Datamart Platform Studio представляет собой совокупность трех взаимодействующих между собой кластеров инсталляций приложений:
Приложение |
Состав |
Минимально рекомендуемое количество инсталляций |
|---|---|---|
PostgreSQL Cluster DCS |
Consul |
3 |
PostgreSQL Cluster Database |
Postgres, Patroni |
2 |
PostgreSQL Cluster LB |
haproxy, keepalived |
2 |
- 1
содержит Consul для Postgres и etcd для Pangolin. Если при установке Postgres необходимо использовать etcd, используйте приложение PostgreSQL Cluster DCS ETCD
Предупреждение
Перед физической установкой кластеров на сервера необходимо произвести предварительную конфигурацию настроек и интерфейсов взаимодействия для кластера.
Настройка параметров приложений кластера должна обязательно производится в карточке кластера, а не отдельного приложения в кластере.
Установка должна производится в следующей последовательности:
Установить кластер Postgres DSC.
Примечание
Для кластера DCS требуется обязательно нечетное количество инстансов (3 и более)
Установить кластер Postgres DB.
Установить кластер балансировшика PostgreSQL Cluster LB.
Настройка IP балансировщика для PostgreSQL Cluster LB
Примечание
IP балансировщика кластера используется для балансировки нагрузки. В этот параметр настройки кластера необходимо вписать свободный ip из подсети, в которой устанавливается кластер. Подключение к кластеру Postgres должно осуществляться по ip-адресу, указанному в настройках балансировщика.
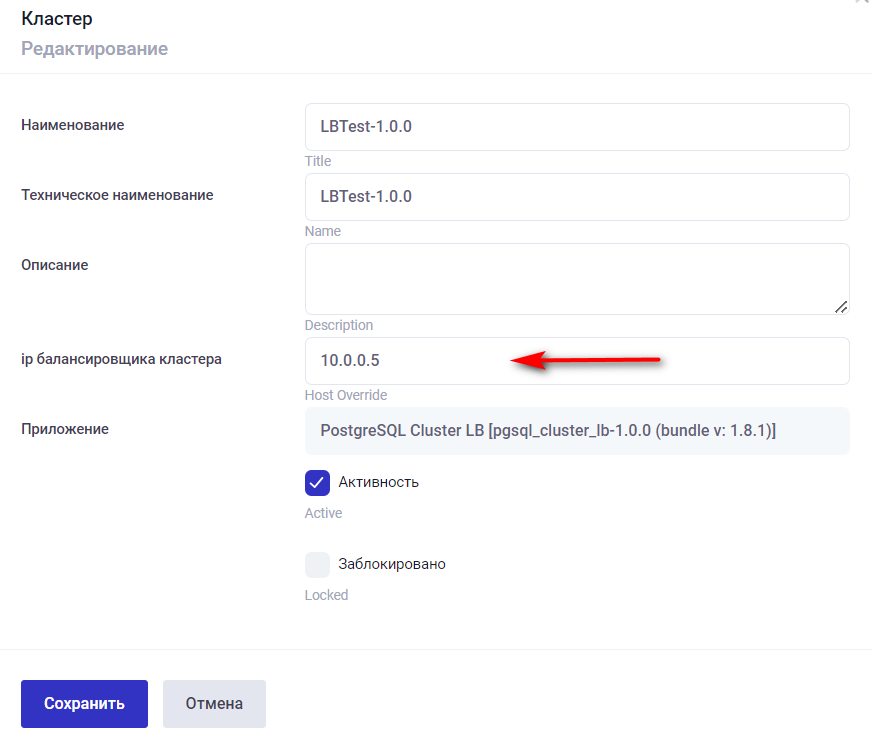
Рисунок 10.5 Настройка ip-адреса балансировщика для Cluster LB
Пример полезной команды на поиск свободного ip в подсети:
nmap -sn -PE -v 172.24.19.14/20 | grep -i down
Для кластера PostgreSQL Cluster LB параметр KEEPALIVED_VIRTUAL_IP указывается в настройках кластера в поле **ip балансировщика кластера** , как показано на рисунке:
Состав интерфейсов балансировщика кластера для операций чтения-записи по умолчанию следующий:
Write:
* техническое наименование: postgresql_write
* порт: 6432
* протокол: TCP
* формат: PGSQLW
Read:
* техническое наименование: postgresql_read
* порт: 7432
* протокол: TCP
* формат: PGSQLR
Настройка параметров кластера PostgreSQL Cluster Database
В настройках кластера PostgreSQL меняем параметры конфигурации:
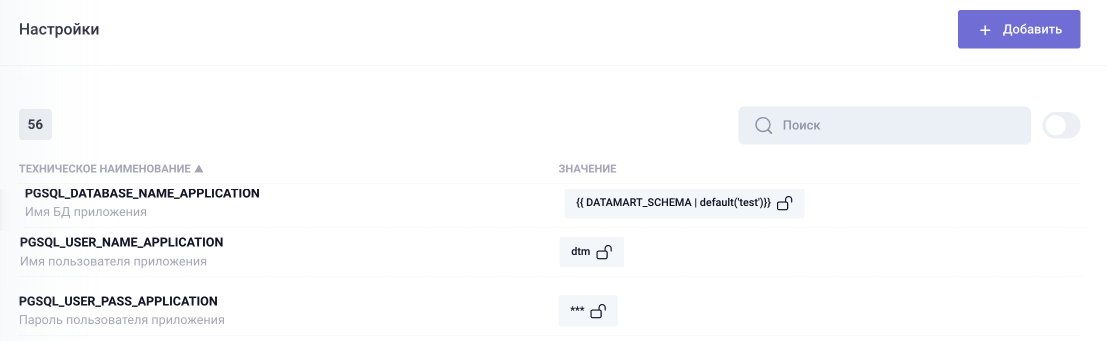
Рисунок 10.6 Параметры настройки PostgreSQL
Кроме этого, для кластера PG DB Cluster необходимо уточнить и прописать в настройки параметра PGSQL_HBA_ALLOWED_NETS подсеть, в которой работает кластер:

Рисунок 10.7 Подсеть кластера PostgreSQL
Внесение корректировок в настройку связей интерфейсов инсталляций (при необходимости)
Для работы с кластером Postgres приложений dtm-query-execution-core, kafka-postgres-writer, kafka-postgres-reader необходимо настроить взаимодействие с интерфейсами балансировщика PostgreSQL Cluster LB для Postgres: postgresql_write и postgresql_read.
Данные связи интерфейсов инсталляций в Datamart Platform Studio устанавливаются автоматически. В случае использования нестандартных портов связи надо установить вручную.
10.5.4.1. Схема развертывания кластера Postgres в минимальной конфигурации
Примечание
В текущем разделе описывается установка кластера Postgres. Установка кластера Pangolin производится аналогичным образом.
Схема, по которой производится установка кластера СУБД Postgres в минимальной конфигурации для Витрин данных с показателем уровня доступности 99.5% приводится на рисунке:
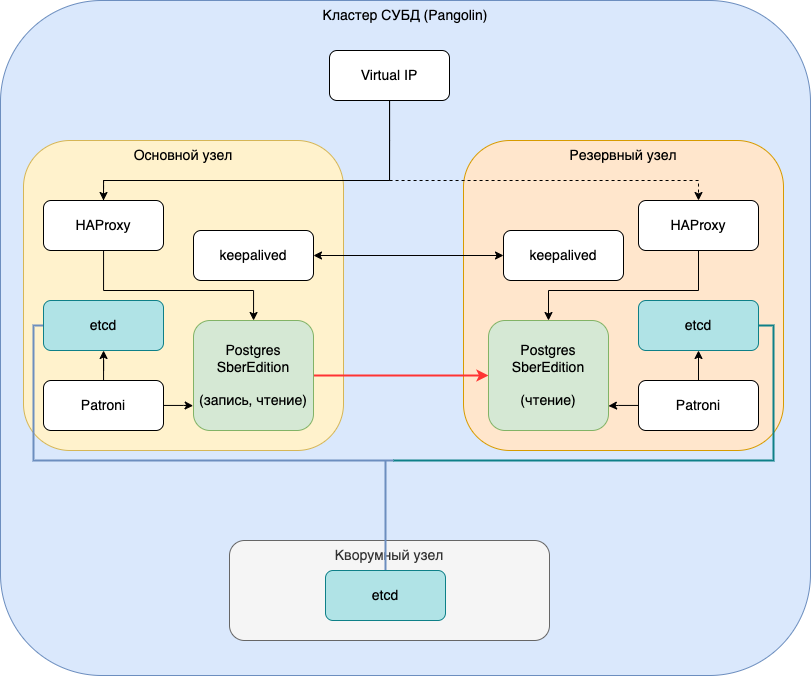
Рисунок 10.8 Схема развертывания кластера СУБД Postgres в минимальной конфигурации
Рекомендуемое распределение инсталляций кластеров приложений по ВМ:
ВМ |
Cluster DCS |
Cluster DB |
haproxy-keepalived |
|---|---|---|---|
ВМ 1 |
|||
ВМ 2 |
|||
ВМ 3 |
При установке Витрин данных, совместно с использованием брокера сообщений Kafka (Corax), рекомендуется установка инсталляций haproxy-keepalived на ВМ, на которых одновременно устанавливается кластер Kafka (Corax).
ВМ |
Cluster DCS |
Cluster DB |
haproxy-keepalived |
Kafka (Corax) |
|---|---|---|---|---|
ВМ 1 |
||||
ВМ 2 |
||||
ВМ 3 |
||||
ВМ 4 |
||||
ВМ 5 |
||||
ВМ 6 |
10.5.4.2. Переустановка отдельных компонентов кластера Postgres
Если в процессе эксплуатации требуется переустановка одного из кластеров, то следует соблюдать следующие правила:
Переустановка PostgreSQL Cluster LB (HAProxy) может быть выполнена независимо от DCS и DB.
Если нужно переустановить DCS, то DB также переустанавливаем. Если нужно переустановить DB, то DCS также требует переустановки.
Для последовательной переустановки кластеров DCS-DB:
Деинсталляцию кластера DB;
Переустановку кластера DCS (можно выполнить отдельно деинсталляцию и затем установку);
Установку кластера DB;
10.5.5. Установка и настройка кластера приложений Ядра Prostore версии 6.10 и выше
Для установки кластера Ядра Prostore версии 6.10 и выше требуется производить установку приложения из кластерного бандла dms-bundle-prostore-6.10.0-ha (бандл с haproxy).
Кластер Prostore функционирует как набор отдельных приложений в Datamart Platform Studio. Для него не требуется создавать компонент «Кластер».
Установка должна производится в следующей последовательности:
Установить универсальный балансировщик для кластеров в Datamart Platform Studio, как это описано в разделе: Раздел 10.3 Создание универсального балансировщика для кластеров
Примечание
Универсальный балансировщик haproxy-keepalived может быть установлен заранее, если он используется для балансировки нескольких кластеров в рамках одной услуги. Повторная установка haproxy-keepalived не требуется.
Установить инсталляции Ядра Prostore на разных серверах (для отказоустойчивой конфигурации достаточно 2х серверов).
Установить конфигурацию haproxy для кластера Ядра Prostore путем установки на серверы с универсальным балансировщиком haproxy-keepalived инсталляций конфигурационного приложения DTM HAproxy LB (техническое наименование: dtm_haproxy), соответственно, по количеству инсталляций haproxy-keepalived.
Подключение к кластеру Ядра Prostore должно осуществяться по адресу, указанному в настройках кластера haproxy-keepalived .
Примечание
Установка и конфигурирование кластера Ядра Prostore версии ниже 6.10 должна производится согласно алгоритму описанному в документации соответствующих версий Ядра Prostore (см. Документация Ядра Prostore )
10.5.6. Установка и настройка кластера СМЭВ QL
Для установки кластера СМЭВ QL требуется производить установку приложения из кластерного бандла Сервис smevql для Витрины Данных для работы с haproxy.
Установка должна производится в следующей последовательности:
Установить универсальный балансировщик для кластеров в Datamart Platform Studio, как это описано в разделе: Раздел 10.3 Создание универсального балансировщика для кластеров
Примечание
Универсальный балансировщик haproxy-keepalived может быть установлен заранее, если он используется для балансировки нескольких кластеров в рамках одной услуги. Повторная установка haproxy-keepalived не требуется.
Установить инсталляции СМЭВ QL на разных серверах (для отказоустойчивой конфигурации достаточно 2х серверов) и объединить из в кластер как это описано в разделе: Раздел 10.2 Добавление кластеров приложений.
Установить конфигурацию haproxy для кластера СМЭВ QL путем установки на серверы с универсальным балансировщиком haproxy-keepalived инсталляций конфигурационного приложения HAproxy-LB-Smevql (техническое наименование: smevql_haproxy), соответственно, по количеству инсталляций haproxy-keepalived.
Подключение к кластеру СМЭВ QL должно осуществляться по адресу, указанному в настройках кластера haproxy-keepalived .
10.6. Пример настройки подключения к внешним сервисам кластеров для ГосТех
При разворачивании Datamart Platform Studio в качестве отдельного Сервиса оркестрации для обеспечения SLA 99.9% требуется настройка подключения Услуги к сервисам, поставляемым в рамках параметра «Сервис оркестрации»: СУБД Pangolin («Сервис транзакционной СУБД (услуга 1.1)») и сервису потоковой обработки данных Corax («Сервис управления очередями сообщений (услуга 1.10)»).
10.6.1. Требования к настройке кластеров для взаимодействия с Витринами данных
Отключение SSL в кластерах Pangolin (Postgres), Corax (Kafka), Zookeeper.
Наличие в Pangolin пользователя dtm.
Наличие в Pangolin у пользователя dtm базы данных витрины.
Наличие в Pangolin в базе данных витрины служебной функции dtmInt32Hash.
CREATE OR REPLACE FUNCTION dtmInt32Hash(bytea) RETURNS integer
AS 'select get_byte($1, 0)+(get_byte($1, 1)<<8)+(get_byte($1, 2)<<16)+(get_byte($1, 3)<<24)' -- little endian
LANGUAGE SQL
IMMUTABLE
LEAKPROOF
RETURNS NULL ON NULL INPUT;
Наличие в Pangolin в базе данных витрины служебного расширения postgres_fdw.
CREATE EXTENSION postgres_fdw;
10.6.2. Настройка подключения к сервису кластерной СУБД Pangolin
Для настройки подключения к сервису кластерной СУБД Pangolin требуется:
Создать публичный входящий интерфейс записи для кластера СУБД Pangolin. В настройках интерфейса указать параметры кластера СУБД Pangolin:
Параметр |
Значение |
Описание |
|---|---|---|
name |
postgresql_write |
Имя публичного интерфейса. Используется для автоматического связывания интерфейсов. |
host |
<ip адрес кластера> |
Выдается администратором сервиса 1.1 |
port |
6432 |
Значение по умолчанию. Используется для автоматического связывания интерфейсов. |
format |
PGSQLW |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
protocol |
TCP |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
Создать публичный входящий интерфейс чтения для кластера СУБД Pangolin. В настройках интерфейса указать параметры кластера СУБД Pangolin:
Параметр |
Значение |
Описание |
|---|---|---|
name |
postgresql_read |
Имя публичного интерфейса. Используется для автоматического связывания интерфейсов. |
host |
<ip адрес кластера> |
Выдается администратором сервиса 1.1 |
port |
7432 |
Значение по умолчанию. Используется для автоматического связывания интерфейсов. |
format |
PGSQLR |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
protocol |
TCP |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
Примечание
При связывании интерфейсов Типового ПО Витрин данных интерфейсы публичные интерфейсы кластера Pangolin будут автоматически привязаны к соответствующим интерфейсам инсталляций приложений: kafka-postgres-reader, kafka-postgres-writer, dtm-execution-core
10.6.3. Настройка подключения к кластеру сервиса потоковой обработки данных Corax
Для настройки подключения к кластеру сервиса потоковой обработки данных Corax (Kafka) требуется:
Создать публичный входящий интерфейс Kafka для входящих подключений. В настройках интерфейса указать параметры кластера Corax:
Параметр |
Значение |
Описание |
|---|---|---|
name |
kafka |
Имя публичного интерфейса. Используется для автоматического связывания интерфейсов. |
host |
<ip адрес кластера> |
Выдается администратором сервиса 1.10 |
port |
9092 |
Значение по умолчанию. Используется для автоматического связывания интерфейсов. |
format |
KAFKA |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
protocol |
TCP |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
Создать публичный входящий интерфейс Kafka для JMX метрик. В настройках интерфейса указать параметры кластера Corax:
Параметр |
Значение |
Описание |
|---|---|---|
name |
kafka_jmx |
Имя публичного интерфейса. Используется для автоматического связывания интерфейсов. |
host |
<ip адрес кластера> |
Выдается администратором сервиса 1.10 |
port |
9999 |
Значение по умолчанию. Используется для автоматического связывания интерфейсов. |
format |
KJMX |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
protocol |
TCP |
Фиксированное значение. Используется для автоматического связывания интерфейсов. |
Примечание
При связывании интерфейсов Типового ПО Витрин данных интерфейсы публичные интерфейсы кластера Corax будут автоматически привязаны к соответствующим интерфейсам инсталляций приложений.